Muitas pessoas já conhecem o Talend como uma ferramenta de ETL e integração de dados, mas seu potencial vai muito além do que se espera de uma ferramenta deste tipo. Trata-se de um verdadeiro canivete suíço com inúmeros recursos para se conectar com qualquer tipo de fonte, extrair e transformar dados livremente sem se restringir aos componentes padrão e escrever os resultados em qualquer lugar. Falando assim parece mais do mesmo: só mais uma definição de ETL, mas a impressão que fica para quem começa a utilizar o Talend é outra.

Sim, tudo começou como uma ferramenta ETL, mas evoluiu para algo muito maior: uma suíte unificada para gestão de dados, que permite resolver não só as questões de integração – levando o dado de um lado para o outro – mas também refinar a Qualidade dos Dados estendendo as rotinas tradicionais de unificar, remover duplicados ou aplicar aquelas velhas rotinas que parecem ter sido escritas na pedra (pois quando qualquer manutenção é necessária…). É possível fazer muito mais com o Talend, pois ele integra todo o ciclo de vida dos dados, envolvendo todas as pessoas que participam dele em um único pipeline.
Imagine, por exemplo, ler um Data Lake HDFS e capturar os dados refinados diretamente pelos Data Owners e Data Stewards e então cruzar estes dados com absolutamente tudo o que for necessário, realizar inúmera transformações, aplicar regras e, quando alguma coisa fugir do esperado, devolver a tomada de decisão sobre qual dado é melhor para quem efetivamente conhece o dado. Tudo isso através de ferramentas totalmente self-service tão ou mais intuitivas até mesmo que o próprio Excel.
Com o Talend Data Preparation e o Talend Data Stewardship integrados ao Talend Studio é possível fazer exatamente isso.
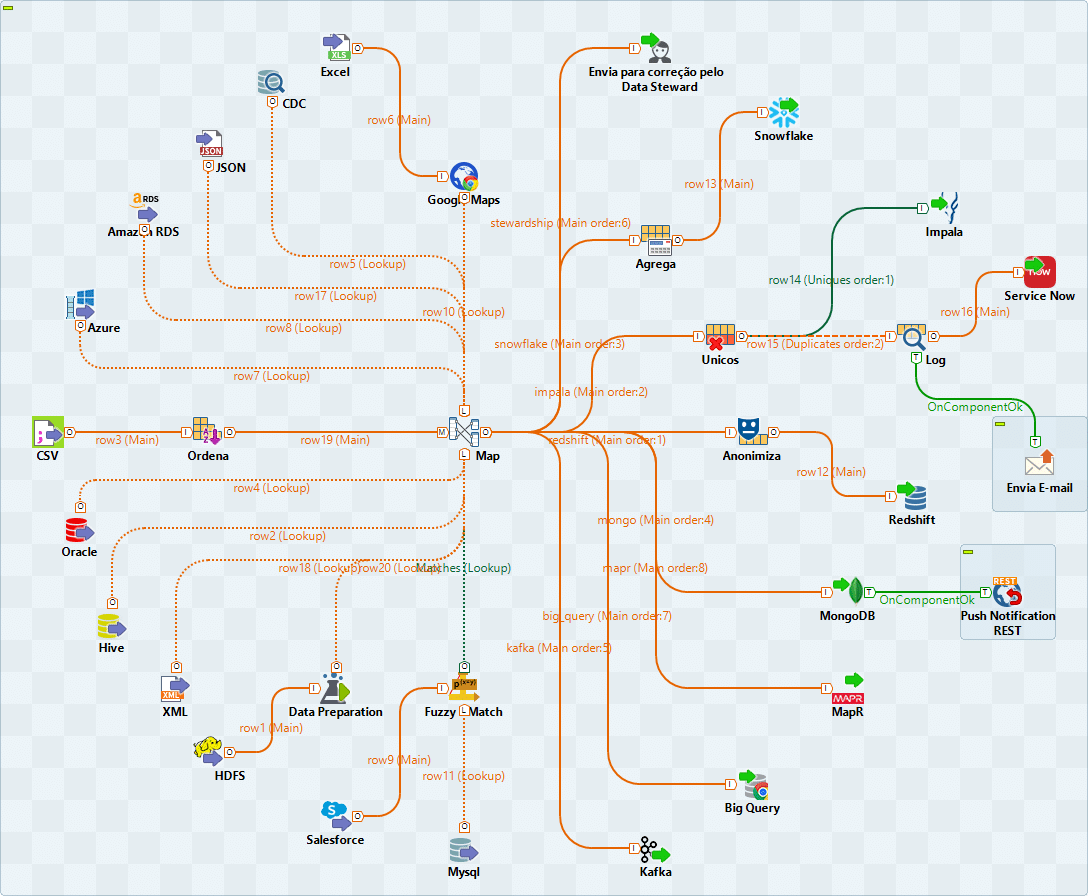
Apesar de pouco convencional, a imagem anterior apresenta um Job totalmente funcional. Um único mapa fazendo a leitura de Azure Storage Queue, Amazon RDS, CDC – Change Data Capture, Microsoft Excel (com enriquecimento dos endereços contidos em uma das colunas através do Google Maps), Oracle, Hive, arquivos CSV, JSON e XML, HDFS (com os dados deste Data Lake refinados através do Talend Data Preparation), Salesforce e Mysql (com um cruzamento Fuzzy entre estes dois últimos).
E então, neste mesmo mapa, a escrita dos resultados em um tópico Kafka, tabelas do Google Big Query, MapR, Amazon Redshift (após a devida anonimização dos dados conforme a Lei Geral de Proteção de Dados – LGPD), escrita dos registros únicos no Apache Impala (e os duplicados enviados por e-mail e para uma API Service Now), Snowflake, MongoDB (com o envio de uma push notification através de um serviço REST após a carga) e, por fim, aqueles registros que não passaram nas regras determinadas neste mapa são devolvidos para verificação pelos seus Owners através do Talend Data Stewardship.
É muita coisa para se descrever em um breve texto e não falamos nem de 1% do que essa solução é capaz. O melhor de tudo é que você pode clicar na imagem acima para ampliar e tudo estará tão intuitivo e auto-documentado que irá dispensar mais descrições.
E se você precisar saber mais sobre como extrair o máximo dos seus dados com essa poderosa solução, e quiser saber mais sobre treinamentos e custos do produto fique à vontade para entrar em contato conosco através do formulário abaixo.
